
“First thing on the job, you know what I learned? How to spot a murderer. Let’s say you arrest three guys for the same killing. You put them all in jail overnight. The next morning, whoever’s sleeping is your man. You see, if you’re guilty, you know you’re caught, you get some rest, and you let your guard down.”
I’ll be the first to say I don’t know much about law enforcement, but I do know movies. That quote is from Agent Kujan in “The Usual Suspects” (the best crime caper film in the last 25 years, but I digress). When it was time to continue our “7 Habits” blog series and cover the topic of “Accelerating Root-cause Analysis” I knew exactly how to start the article. After all, what are system and network administrators doing in trying to solve a problem impacting their IT infrastructure? They’re engaging in a good old-fashioned “whodunit”. However, instead of trench coats and Briar pipes, the tools of this trade are dashboards, log messages, and Netflow packets
Before we go any further let’s clarify our definitions. Translated into plain English, so everybody understands, “Root-cause Analysis” (RCA) basically means getting to the real root of a problem. Did you suddenly get bandwidth, CPU, and DOWN alerts from three different servers on your network simultaneously? It would be highly coincidental if all three had separate and discrete failures. The reality is that each alert is likely connected in some manner. RCA means figuring out that relation and solving the problem at its core. Hopefully, it’s obvious why taking this kind of action is beneficial. From a technical standpoint, if you don’t figure out the root cause of the alerts, then the likelihood of it happening again is pretty high. From a business standpoint, when you and your team are constantly chasing your tails, troubleshooting symptoms of a problem rather than its cause it’s an inefficient and ineffective waste of your time. Even for engineers on the front lines of IT time is money.
Visualize this scene: It’s time for the weekly “All-Hands” Information Systems team meeting. Your organization’s Pointy-Haired IT Boss says, “I want to maximize our team synergies and prioritize the acceleration of root-cause analysis, so we’re more effective partners to the rest of our business units.” MBA-gibberish aside, this task is much easier said than done. The key to a good RCA strategy is having the tools in your arsenal that can help you get there.
First on the list is a management system that provides a far-reaching, but flexible single pane of glass into your IT infrastructure. Let’s unpack that last sentence because it’s an important point. There are many common elements to today’s typical IT architecture: Networking gear, servers, and applications are elements that come to mind immediately. However, there are smaller subsets to consider too. What about SDN and other cloud-based resources? What protocols does your NMS need to listen for in order to digest all that diagnostic information? You need a high-level NMS dashboard that not only shows you a concise roll-up of statuses, but also allows a very quick drill-in access to CRITICAL conditions, and relevant details, when they occur.
A single pane of glass into all your systems is good (and necessary), but it’s not the whole enchilada. There are as many applications in common use today, as there are different types of businesses. At a technical level an ERP package for a manufacturing company likely has different parts and pieces than an ERP system for a large retail chain. Those systems need to be monitored nevertheless. Therefore, you want to have the capability to quickly and easily teach your NMS what kind of alarms should be related to one another and what types need higher prioritization. Taking advantage of this type of capability kills two birds with a single stone. First, you’re reducing the number of alerts that are actually leaving your NMS and ending up in your staffs’ inboxes. Second, when the user interface of your NMS tool has a visual queue advertising an application problem, then teaching it what other monitored components are part of that application saves you troubleshooting time and effort in the long run.
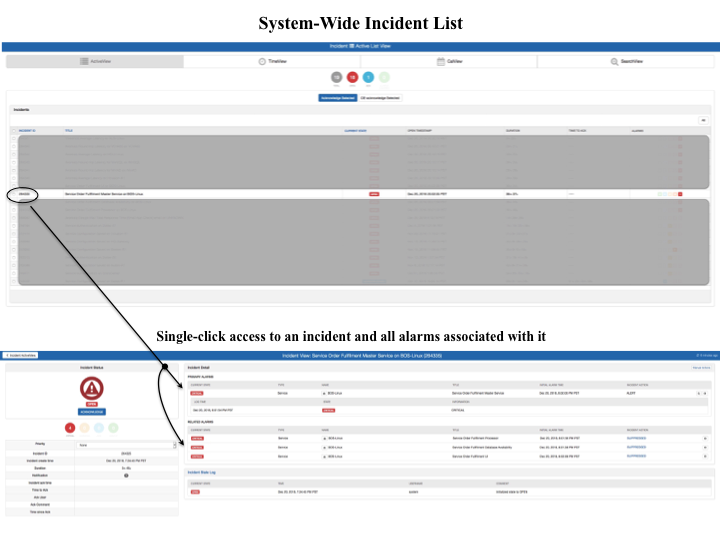
A third arrow in your RCA quiver is auto-discovery capabilities. Ideally, you can leverage these capabilities in your environment without having to seed your NMS with application information. The primary example here is network topology mapping. Using protocols like ICMP and CDP hopefully your NMS can figure out traffic paths and distinguish the difference between a device that’s legitimately DOWN versus a device that’s unreachable. That might sound like a simple problem to solve, and for a human it is. However, the part for humans that isn’t easy … the part that takes considerable time and effort … looking through the 25 DOWN alerts that just flooded your inbox. There is no quick way to figure out which device is the root cause of your outage because if NMS cannot create the necessary dependency relationships.

I’ve talked plenty about why accelerated Root-cause Analysis is important, and I’ve waxed poetic on what things to look for in your toolset, but how do we get from points A & B to point C? Luckily, the answer this time around is less complex.
First, at a minimum, make sure whatever monitoring tools you’re planning on deploying have the features I’ve already mentioned, or at least get close to it. Some management tools will be more infrastructure-focused and some will concentrate on actual application performance instead. The key is to find the right balance between costs and functionality.
Secondly, take a step back and analyze your systems. Don’t limit this analysis to only physical/virtual assets, but include applications and their criticality to your business as well. What kinds of alerts (and how many) has your team received in the last 30 days? How does your ERP system integrate with your Order Fulfillment System, for example? Armed with this information and robust monitoring tool you’ll be well on your way to accelerating RCA improving MTTR in your organization.
One aspect of systems administration and post-sales technical support roles I’ve always found most appealing is the detective-like nature of the work. When solving a technical issue and given a specific problem domain, it’s only a matter of time before your typical engineer will answer the critical question of “Whodunit”. Given the deployment of the proper tools and planning, you can get to that answer faster. Will it win you an Oscar or critical acclaim? Probably not, but it’ll certainly make your Pointy-Haired Boss happy.







