
Network & Systems Administrators are the backbone of any IT organization.
They provide critical monitoring and support for all IT resources—be they networks, SD-WANs, servers, apps, or virtual and cloud resources.
After working with hundreds of Network & Sys Admins, we’ve identified 7 crucial habits of the most effective ones.
A typical Network or Systems Admin receives as many as 200 alerts/day. As many as 80% of these can be triggered during regular work hours. That means an average of 160 alerts need triaging in a 10-12 hour work day. This comes to about 1 alert every 5 minutes!
Most of these alerts are either redundant or lower priority, and can be triaged easily. However, it still takes time and manual effort to triage them.
Not only is the task of triaging redundant and low priority alerts overwhelming, it also has sinister side effects on a Network Admin’s work.
The most effective Network and Systems Admins have realized that, for them to be productive and useful to their teams, they have to deal with this problem head on. Their solution:
At any given time, Network or Systems Admins have to monitor at least 10 to 12 different type of resources.
As we mentioned above, these include networks, SD-WANs, server workloads, apps, and virtualized and cloud resources.
On top of that, each resource will have its own tools. For example, networks use Network Management Systems like Zabbix and Xymon, virtualized server workloads use tools like vCenter, applications use APM (New Relic and AppDynamics), and cloud resources like Meraki have their own separate view into their hardware.
Each tool comes with its own dashboard.
Many claim to provide a “Single Pane Of Glass” (SPOG) view. But, not all live up to the claim. Ideally, a Single Pane Of Glass should demonstrate these three characteristics:
For example, here is a sample screenshot of what a real SPOG should be able to produce.
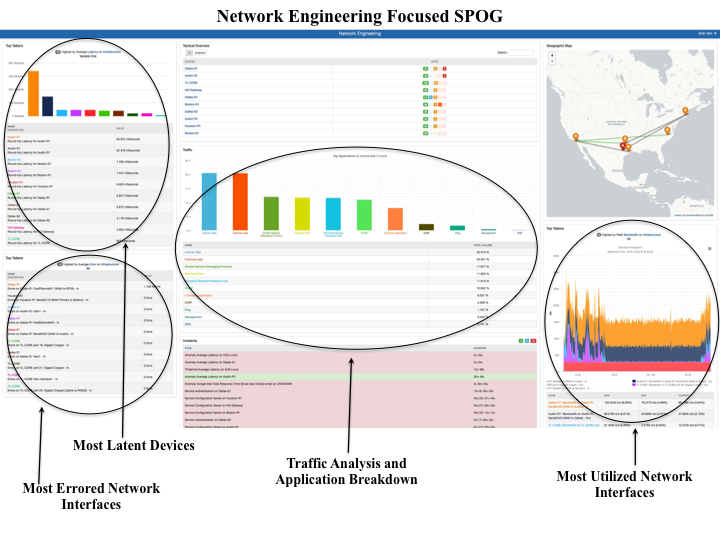
There are only a handful of tools that can claim a real SPOG. Among the products prevalent in the field are IBM Tivoli, EMC Smarts and Netreo OmniCenter. (We’re currently working on a handy blog post to help you determine if your SPOG is really a SPOG. So be on the lookout for that in the near future.)
Ask any Network or Systems Admin how they spend the majority of their time, and the most common answer you’ll get is: fighting fires.
These folks also acknowledge that the most pressing problems boil down to only three things:
We’ve already addressed the redundant alert problem above.
For the remaining two, automation is the key.
The most effective Network and Systems Admins work ruthlessly at automating all the tasks they can. However, before they start, they need to figure out two fundamental things:
Surprisingly, determining what to automate can be almost as complex as how to do it.
So, how do the most effective Network and Systems Admins build their prioritized list for automation? Well, it starts with an understanding that their daily activities can be broken down into four broad categories:
Today, new resources come online every minute. To ensure that they comply with your information systems policies, all resources should be:
The most effective Network and Systems Admins recognize the importance of these directives and deploy a template-based solution to address them.
An excellent example here would be the monitoring of memory utilization on Microsoft SQL servers. It is well known that MS SQL systems will use all of the memory allocated to them. Therefore, it follows that you’d want a different template that applies to your SQL Server infrastructure as opposed to your MS Windows servers running middleware applications. Your SQL servers have special operating parameter not present elsewhere.
Templatization isn’t easy. You have to understand the pattern for each templatized resource/workflow. You also have to build your corporate policies and expectations into the developed templates. Finally, all templates must be versioned, saved and backed-up automatically.
If you’re already using the techniques listed up to this point, chances are you’ve already eliminated 50-60% of your potential problems. You’re also most likely already recognized as a highly effective Network or Systems Admin, and your peers likely come to you for help and advice.
But while you’re advising them, and discussing the philosophy of changes IT will go through over the next 5 years, yet another resource failure is detected. Its status turns red and the alerts start to come in. But, because you have already eliminated 80% of the redundant alerts, and automated a huge chunk of triage work an average administrator has to perform, you know that this problem is no false alarm.
The whole team is now racing to find the root cause. Every minute spent on decoding the problem means one more minute of disruption. You don’t like it. Your boss doesn’t like it. And, above all, your customers don’t like it.
But, as an effective Network or Systems Administrator, you have one more ace up your sleeve.
Within minutes, you know exactly how and where to look for the problem and perform a root cause analysis.
Along with automation, the most effective Network and Systems Administrators understand that having access to the right tools, that not only show a consolidated dashboard but also come with one click drill downs, is the key to success and happy customers (and a happy manager too).
Combined with a proper Single Pane Of Glass, these tools are so effective that they can save you 10-15 hours each week! (That’s like having one free day every work week!)
Here’s an example of how a one click drill down capability should work.
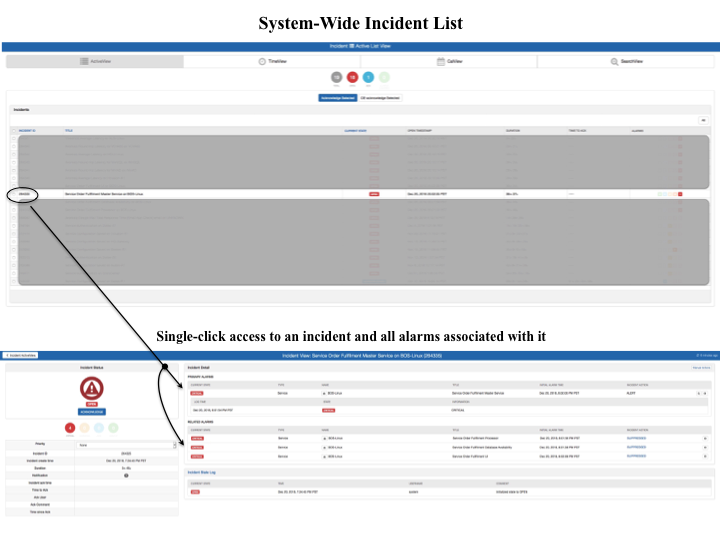
As we discussed earlier, a typical Network or Systems Admin has about 10-12 tools available to them to monitor their IT resources.
At least a few of these can take months to configure, deploy and customize. And, vendors typically don’t mention the large and complex infrastructures required to support their tools.
The most effective Network and Systems Administrators understand two important things about such tools:
So how do they pare this large list of tools down to the most productive ones?
Stated simply, the most effective Network and Systems Administrators ask vendors one key question, “What’s the cost of managing your management system?”
They then ruthlessly kick out any offending products.
An “offending product” is any IT management software that violates the 4 principles of modern management platforms.
For all the tools Network and Systems Administrators have, failures are still often reported by the users.
This tends to happen because all monitoring tools work off of thresholds set by someone other than the end-user of the resource. Even most Network or Systems Admins don’t have full control over all the thresholds across all the tools they have to use.
This results in one of the two things:
The most effective Network and Systems Administrators understand that the solution is not to simply tweak alert thresholds.
Instead, they develop a comprehensive strategy to go from reporting failures to predicting them.
How do they do that?
By deploying solutions with built-in predictive reporting capabilities.
Using data from the past load, thresholds and available resources, the predictive reporting engine applies machine learning (ML) algorithms to determine if there is a real possibility of failure or not.
Here’s a good example of a set of predictive reports.

We’ve covered predictive reporting before—and even proposed a solution. However, be mindful that this is still an evolving technology.
That was a lot of information. But, if put into practice, these seven habits can take your team from just being good to being great!
If you know more techniques or would like us to explain anything in more detail, leave a comment below. Netreo has the tools you need to do what you want.







